Feature flags are a very powerful software development tool that allows you to enable or disable functionality at runtime. This is very useful if you wish to deploy changes to sets of production users and, for example, experiment on the features’ performance. They are also commonly used to disable features in case they are harming users.
This is an alluring ability. However, the abuse of this technique can lead to unforeseen consequences, impacting the agility of your system to be maintained and updated by your team.
They add complexity
Simply, feature flags are an added branching point in your code. Depending on how your team defines ‘features’ and the requirements of when to add a feature flag, their use is potentially going to lead to a huge increase in the complexity of your code, compared to if you were not to use them.
Understanding the code is harder
Take a simple case of reading the lines of code in a method. You’ll typically parse it line by line, jumping to other method calls it makes, storing in a mental stack each step that preceded, as you try to understand the responsibilities of the method. Each conditional statement is a branch in the execution path that adds a level of difficulty to the mental juggling you do to gain an understanding.
If your feature flag use in the codebase is remotely prolific, and if your team doesn’t have a strict process for cleaning the flags up after a set amount of time, there will be numerous extra branches to parse through. Inevitably this will result in a codebase that is incredibly difficult to understand, as you search through what features are enabled/disabled, to understand the ‘active’ path through the code. This ultimately becomes a maintainability nightmare.
Clean them up
To help avoid some of the problems with the use of feature flags, one thing your team can do to improve things is to have a strategy for removing them after a certain period.
Ideally, you will have some automation that expires feature flags after a certain amount of time, incentivising engineers to clean up their old ones. You could also limit the number of feature flags allowed in your system at one time so that to add a new one you must clean up an old one.
What does overusing them tell us about the system
If a system becomes overreliant on the use of feature flags, especially for mitigation of incidents, it indicates a couple of things about the system. Feature flags can become a crutch in the case that deployment pipelines and rollbacks are not quick enough to satisfy mitigation requirements. Their overuse also indicates a gap in automation testing or feature-specific monitoring.
What are your other options?
So a great place to invest your effort is improving the efficiency of your deployment pipeline. If you can deploy faster, you’re more likely to deploy more frequently. This will inevitably result in smaller payloads being shipped to production, making it easier to pin down problematic changes. This will also result in the quicker ability to release a hotfix if you identify a problem with a feature in production. Meaning you’re not solely reliant on the use of feature flags for issue mitigation.
Aside from investing in speed, you can also apply a strategy known as blue/green deployment. Blue/green deployments are a technique where you maintain two instances (slices) of your service running build N and N+1, serving all live traffic (blue) and the other running on standby without any traffic (green) respectively. Whenever you deploy a new payload to production, you deploy it to the ‘dark’ (not serving live traffic) slice, in this case, the green slice. Then, using your load balancer, you switch all traffic to the green slice. You repeat this procedure for each deployment.
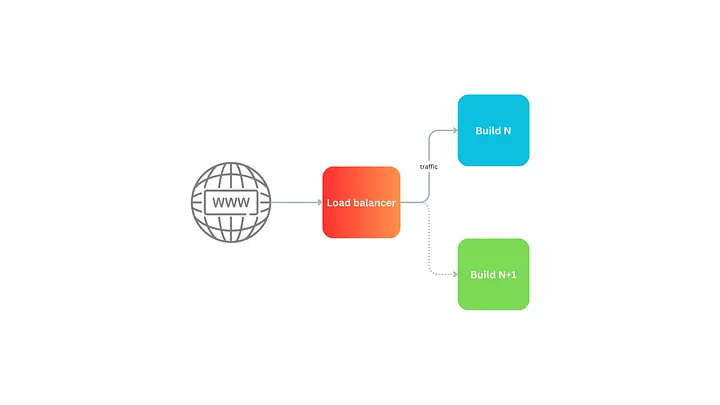
The benefit of this deployment strategy is if you discover there is some issue with the new build, the rollback procedure is very fast as you just switch all traffic back to the old build in the blue slice.
Another cool thing you can do with Blue/Green deployments is once you have pushed the new payload to the ‘dark’ slice, you can duplicate real requests from the ‘live’ slice and monitor how they behave on the new payload, without impacting any real users. This is a great way to verify a build’s stability with real traffic but without any risk to customer experience.
Use them wisely
I’m not saying throw away feature flags. They are a very useful tool in the maintenance of a production system. I just want to warn you that, like most things, you can get too much of a good thing. Use them sparingly, and you will reap their benefits. However, fall into the trap of abusing them, and you will see the problems that come with it.